
Unlock the solutions that can propel your business forward.
Request a strategy session to learn how to automate and optimize your operations.
A Lab Manager's Story: Beyond the Secret Sauce
I’ve been managing labs for a long time, and if there’s one question I get asked, it’s whether there's a "secret sauce" to preventing production outages. My answer is always the same: probably not. But I can tell you that the costly, headline-grabbing service disruptions we’ve all seen are almost always preventable. I’ve seen it firsthand, from the front lines, how the likelihood and impact of a critical outage are drastically reduced when we prioritize one thing above all else: rigorous, relentless pre-production testing.
We’ve all read the stories, and they make me cringe every time. A single software update, deployed with confidence, takes down a nationwide network. A simple configuration error, overlooked in a late-night change, disrupts emergency services for millions. As the manager of a managed services team, I see our role as a critical partner in our client's defence against these kinds of disasters. In today's market, where their customer's trust can be lost in an instant, helping them build resilient systems isn't just a best practice, it's our most important job.
And it’s why operators trust us with their labs. They face immense pressure to innovate and deliver new features, but their progress can be stalled by a host of complex issues: contention for limited lab resources, unexpected maintenance windows that halt testing, or stubborn software bugs that defy easy explanation. Any one of these delays can mean missing a critical market window and impacting revenue. Our mission is to take on that complexity, allowing their brilliant engineers to focus on innovation while we provide a stable, reliable environment. We continuously improve the lab's performance and provide the hard metrics to prove it.
How We Build a Resilient Lab: Our People and Our Process
Lab availability isn’t a single process. For us, it’s a mindset driven by a dedicated team and a framework of control, detection, and rapid recovery. When we take on a lab, we accept that failures and constant change are guaranteed. Our strategy is built around turning that potential chaos into a well-managed, predictable operation.
This requires a multi-faceted approach, where each element plays a critical role:
- The Ticket Management & Incident Response Team: These are our frontline problem-solvers. They manage the entire lifecycle of an issue, from the initial triage and detailed documentation to escalating it to the right network function owners or vendors. Their focus is on rapid resolution, especially for high-severity tickets where every minute of downtime is a minute a client's team can't test. They are the reason we can recover from issues so quickly, turning a potential crisis into a managed event.
- The Proactive Monitoring & Health Check Team: This team’s goal is to find problems before anyone else does, often while the client's engineers are asleep. Using a suite of automated tools that run 24/7, they continuously run health checks across the entire lab environment, from the core network functions to the application layers. Their early detection, finding a degraded service at 3 AM instead of 9 AM, is what allows us to be proactive, not just reactive, and maintain momentum.
- The Change Management & Coordination Team: In a lab, unmanaged change is the enemy of stability. I've seen situations where two separate teams, unaware of each other's work, make conflicting changes that bring a system to its knees. This team prevents that. They ensure every activity that could impact the lab, from a software patch to a network reconfiguration, goes through a formal approval and scheduling process. They publish these schedules so everyone is aware, preventing surprise disruptions and hours of wasted diagnostic time.
- A Culture of Automation: Underlying everything we do is a commitment to automation. We have a simple rule: if you have to do something more than twice, it's time to automate it. This isn't just about writing scripts; it's a cultural mindset. We encourage our teams to meticulously document any repeatable task, from running a health check to deploying a new software build, and then turn that documentation into a robust, automated process. Automation not only accelerates these tasks dramatically but, more importantly, it makes them less prone to the inevitable errors that come with manual execution. This frees up our talented engineers from repetitive work and allows them to focus on complex problem-solving, which is where they add the most value.
The Results We're Proud Of
This commitment isn't just about words; it's about delivering measurable results that justify the trust our clients place in us. The data, which we track meticulously, shows the impact of our work.
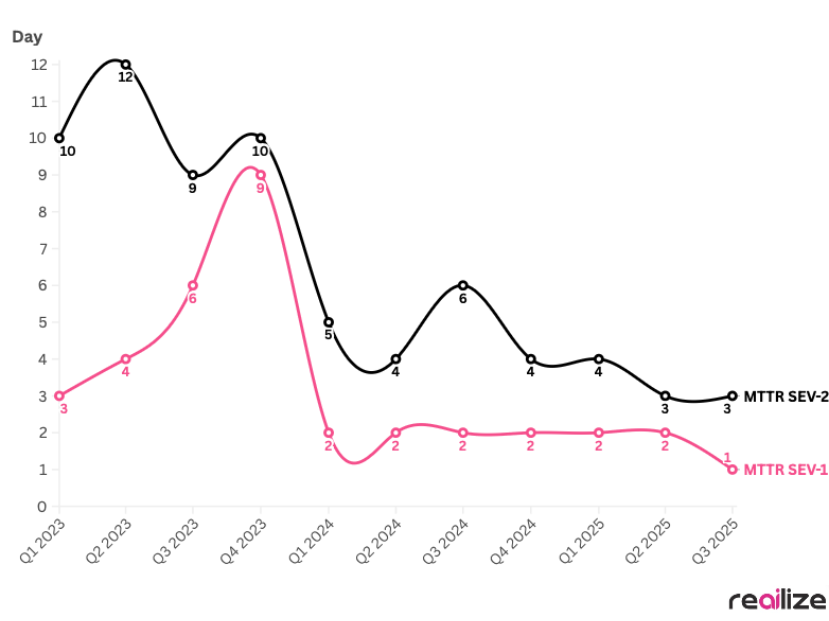
Mean-Time-To-Recover (MTTR)
We slashed the recovery time for the most severe, service-impacting incidents by nearly 90%. As you can see in the chart, we took the resolution time for Sev-1 (highest severity/impacting incident) tickets from a full day's work, a devastating loss of productivity, down to just an hour. This means a critical issue becomes a minor interruption, not a day-long roadblock.
Lab Availability
Even with planned maintenance windows, our focus on proactive monitoring and rapid recovery has allowed us to consistently keep our client's labs running at over 90% availability. This level of reliability builds confidence and creates a positive rhythm for the development teams, who can trust that the environment will be ready for them their activities each day.

These numbers prove that while we can’t prevent every single issue, we’ve built a system and a culture that can handle anything thrown at us, minimizing disruption and maximizing productivity for our client.
My Final Thoughts
The journey to minimize production outages truly begins in the lab. As I’ve learned over my career, when we help our clients create reliable and predictable systems in their development environments, they inevitably create more reliable services for their customers. This idea is perfectly captured by Gene Kim in "The Phoenix Project," where he emphasizes that creating reliable systems in development is a direct prerequisite for creating reliable production systems. By entrusting their lab to a dedicated partner, our clients aren't just investing in processes and metrics; they are investing in a culture of continuous improvement and freeing their own teams to focus on what they do best.
Together, we're not just preventing the next headline; we're building the foundation of trust between our client and their users, one stable test and one resolved ticket at a time. And in my experience, that partnership is everything.
Engage with the Team

